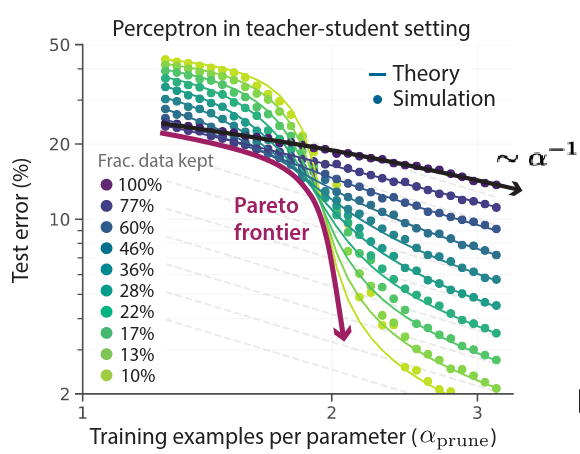
In this paper they show that we can achieve exponential performance scaling over dataset size, when the samples added are pruned to be only the best examples. This beats power law scaling in a big way. There is still no free lunch, in some sense, because in most cases it will become progressively harder to add new useful samples as the dataset gets bigger. But this is a big deal for computation, because it means that the number of samples in the dataset is not nearly as important as the coverage and quality that the dataset provides.This also means that scaling laws for compute (usually expressed as a function of dataset and model size) are dataset-specific and not generalizable, because of how much sample quality affects data scaling.
Unfortunately, the authors found that “dataset pruning strongly increases class imbalance”. To remedy this, they modified their pruning metrics to ensure that every class had at least 50% of the images that it would have if all classes were pruned equally. This leads me to the question: what is the scaling behavior for worst group performance under data pruning?We don’t even know yet what the scaling behavior of worst group performance is without data pruning.
They found that “performance often increased [beyond the results reported in this paper] when the same number [of] training iterations on the full dataset was carried out on the pruned dataset, resulting in … additional training epochs,” but we see in Appendix J that this gain is small (maybe not statistically significant?), and achieved after only 40-60% of the additional epochs required to reach the same number of iterations.