This post was created as an assignment in Bang Liu’s IFT6289 course in winter 2022. The structure of the post follows the structure of the assignment: summarization followed by my own comments.
paper summarization
Word embeddings have gotten so good that state-of-the-art sentence classification can often be achieved with just a one-layer convolutional network on top of those embeddings. This paper dials in on the specifics of training that convolutional layer for this downstream sentence classification task.
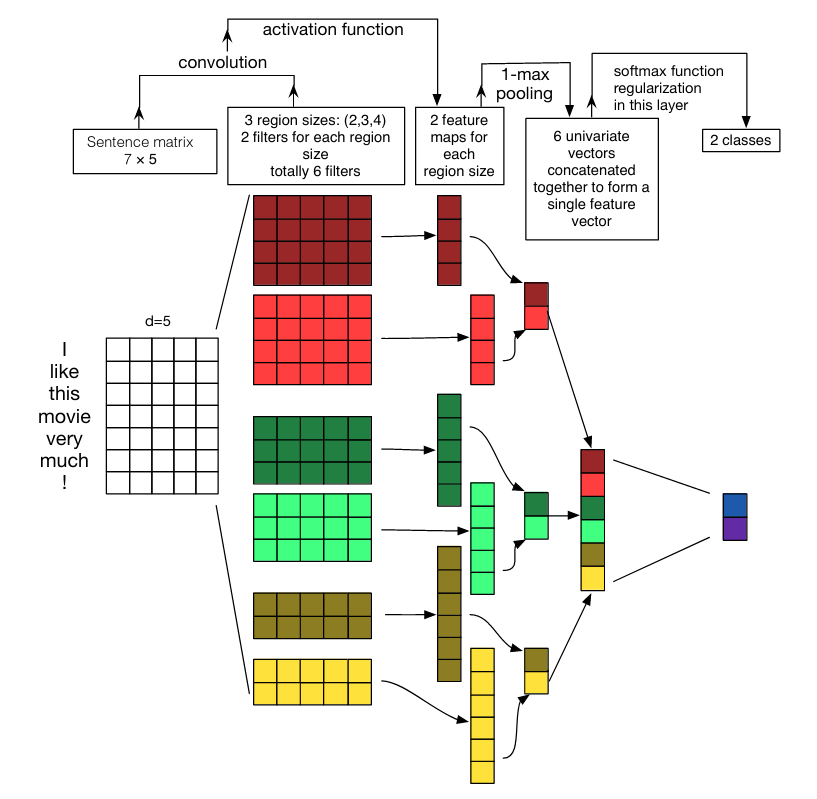
The input to the convolutional network is a matrix containing the word embeddings for all the words in a sentence. When we say convolution, in this case what we mean is sets of filters of varying sizes that are applied across that sentence matrix and then pooled to create the final inputs to a softmax layer. Here are the optimal settings they discovered:
- filter size: different for each dataset, but generally between 1 and 10. A grid search on this hyperparameter might be best. Using multiple filter sizes near the optimal value can improve performance, but adding filter sizes far from this can hurt it.
- number of filters per size: generally 100-600 filters is good.
- activation functions: none, ReLU, or tanh.
- pooling: 1-max pooling outperforms average pooling,
\(k\)-max pooling, and pooling over smaller areas of the feature map. - regularization: dropout appears to have little effect, and L2 norm regularization has adverse effect. This is likely because the network being trained is small and unlikely to overfit.
comments
I worry that this was not a difficult enough problem to robustly observe the effect of the various hyperparameters that were studied. In many cases, the difference in accuracy varied less than 2% (absolute), which might not be significant on such small datasets. (The paper states that the experiments were all performed 10 times, each with 10-fold cross-validation, but I wish the authors had included a study of the statistical significance of their findings.) Also, the experiments generally varied only one parameter at a time, which leaves a lot of the hyperparameter space unexplored.