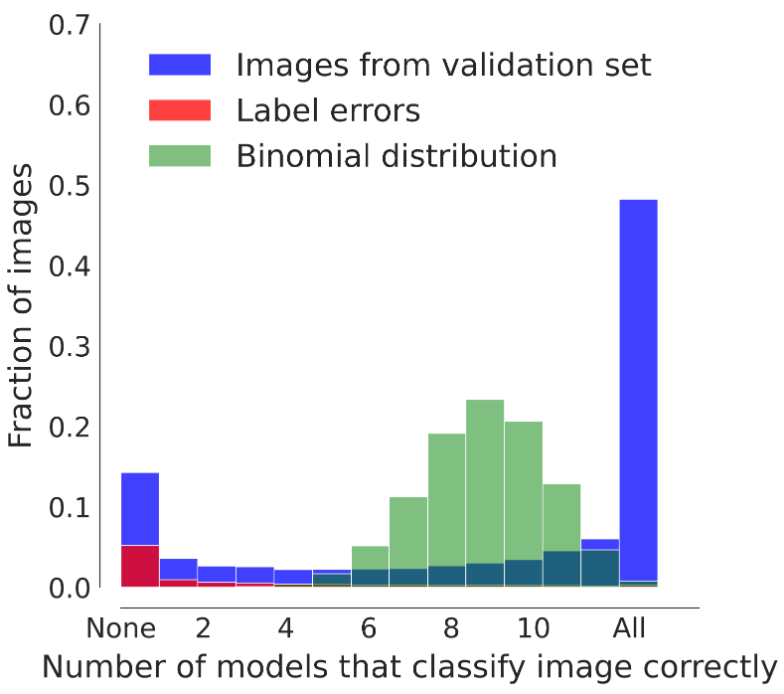
We observe that 48.2% [of] images [in ImageNet] are learned by all models regardless of their inductive bias; 14.3% [of] images are consistently misclassified by all models; only roughly a third (37.5%) of images are responsible for the differences between two models’ decisions. We call this phenomenon dichotomous data difficulty (DDD).
The authors varied hyperparameters, optimizers, architectures, supervision modes, and sampling methods, finding that models only varied in performance on about a third of the images in the dataset. And this isn’t specific to ImageNet; they found similar results for CIFAR-100 and a synthetic Gaussian dataset. They use this measure to divide the dataset into “trivials”, “impossibles”, and “in-betweens”.
They were able to show that the existence of the “impossibles” is not primarily due to label errors. They performed human experiments that showed that untrained humans have a natural intuition for recognizing these “impossible” samples.
I’d be interested to see what data pruning methods do to samples from each of these three classes.