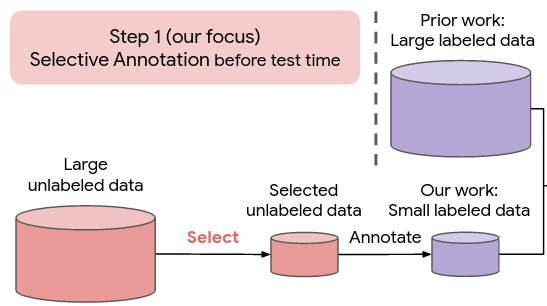
Selective annotation chooses a pool of samples to annotate from a large set of unlabeled data. The main result of the paper is that when this is combined with item-specific prompt retrieval the performance drastically improves (>10% relative gain and lower performance variance). Interestingly, selective annotation does not help for finetuning, or when the prompts are randomly selected. They call their selective annotation method “vote-\(k\)”.
selective annotation method
Vote-\(k\) essentially creates a network of similaraccording to Sentence-BERT
unlabeled instances, and then selects from them with a network importance score that is discounted to promote diversityThe discounting is performed by iteratively adding to the selection set, each time penalizing new nodes for being close to nodes that are already in the selection set.
.
prompt retrieval method
Following previous work, the authors choose prompts for each test instance by finding the annotated prompts closest to it in terms of cosine similarity of the Sentence-BERT embedding.
experiments
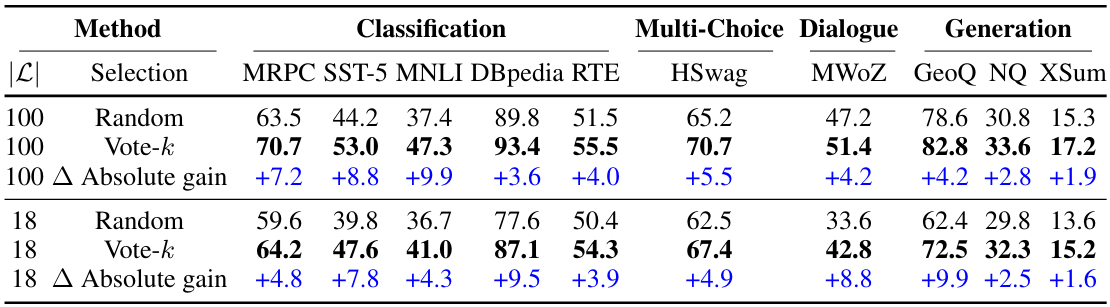
The authors note that vote-\(k\) is deterministic, so they perform selective annotation over random subsets of the original training data for each task, to ensure that experimental results are stable. Here are the main results from the paper:
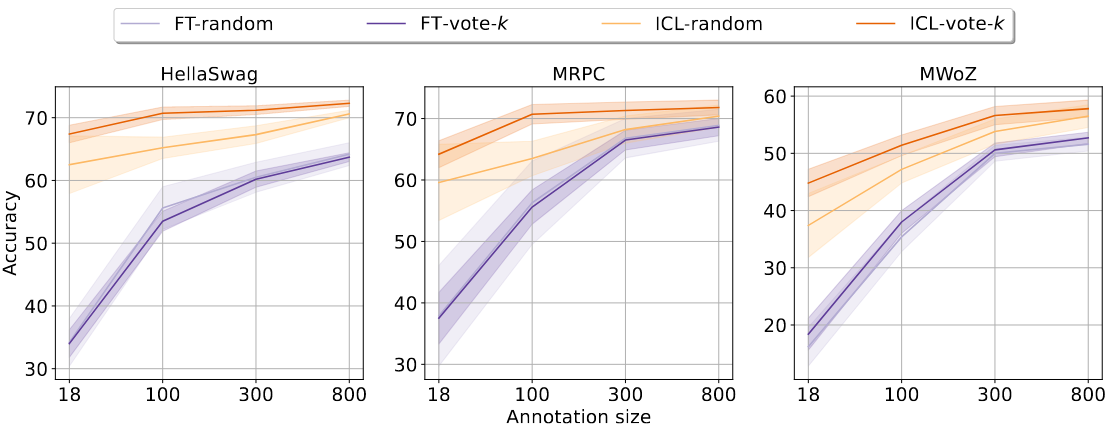
And here are the results when the compare finetuning and prompting over randomly- and vote-\(k\)-selected downstream datasets:
It also looks like vote-\(k\) outperforms several methods from the active learning and coreset selection literature, when they’re applied to this task of selecting data to label for prompting:
