T0 builds on T5 by fine-tuning on more natural prompts and testing the model’s generalization to held-out tasks.
Compare the training format diagrams for T5 (top) and T0 (bottom):
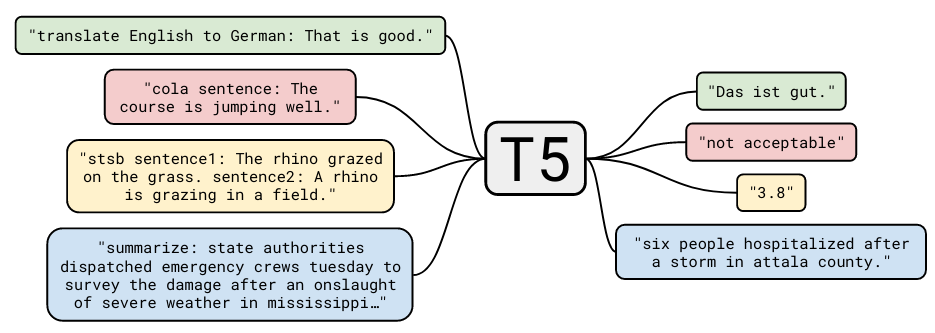
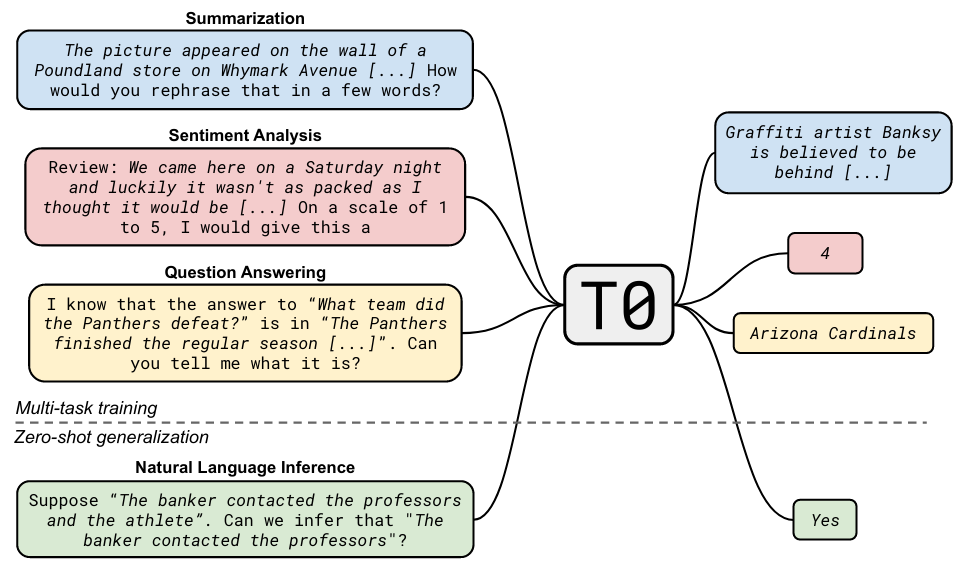
Intuitively, the T0 prompts are more likely to be similar to implicit/explicit prompting that’s present in the pretraining data. The authors created several prompts for each dataset.
results
Our experiments study two questions. First, does multitask prompted training improve generalization to held-out tasks? Second, does training on a wider range of prompts improve robustness to prompt wording? For the first question, we find that multitask training enables zero-shot task generalization by showing that our model matches or exceeds the performance of GPT-3 on 9 out of 11 held-out datasets, despite being about 16x smaller. We also show that the model improves over a large baseline language model on 13 out of 14 tasks in the BIG-bench benchmark. For the second question, we find that training on more prompts per dataset consistently improves the median and decreases the variability of performance on held-out tasks. Training on prompts from a wider range of datasets also generally improves the median but does not consistently decrease the variability.