I think it’s valuable to be working in the open whenever possible, so I’m going to keep my research notes here. These notes will hopefully be full of good (and bad) ideas, so if someone borrows a good idea and publishes on it, that’s great!
This post contains my research notes as I try to understand how model scaling affects worst-group performance. This started as a group project in the neural scaling laws course at Mila in winter 2022. We presented about an existing paper and presented our preliminary results in class. The repository for this project is here.
Here’s my executive summary of what we accomplished during the semester:
- We wrote a solid training routine with the following options:
- We ran one experiment across each combination of options,During the semester we were unable run experiments with ILC for models larger than ResNet18. ILC is very storage intensive because it has to compute masks across individual samples in a batch. We didn’t take the time to try multi-GPU training. and were surprised to find no consistent trends. Often, the difficult part of demonstrating scaling behavior is finding the optimal set of hyperparameters for each size (observable in Deep Learning Scaling is Predictable, Empirically). We expect to see consistency by running more experiments with different seeds and optimizing over hyperparameters.
2022-07-18
This week I got access to some compute with Stability.ai. I’ve started just the pretrained ResNet ERM experiments from the class project but with 10 different seeds for each experiment, so I can get an idea of the variability in performance. Next I’m going to try varying some hyperparameters.I’m trying to decide if I should use hyperopt for this experiment. It seems like the right choice because random search is better than grid search, but it means it will take a lot longer to “get a number” for each individual point on the plots. But it will help me avoid the mistake of placing too much stock in any one hyperparameter value or result. I’ll need to figure out some way to let my hyperparameter priors reflect past experiments when I restart a job.
2022-07-27
Here are the results from the simple experiment I mentioned last time. Each line is averaged over 11 seeds. Click to zoom:
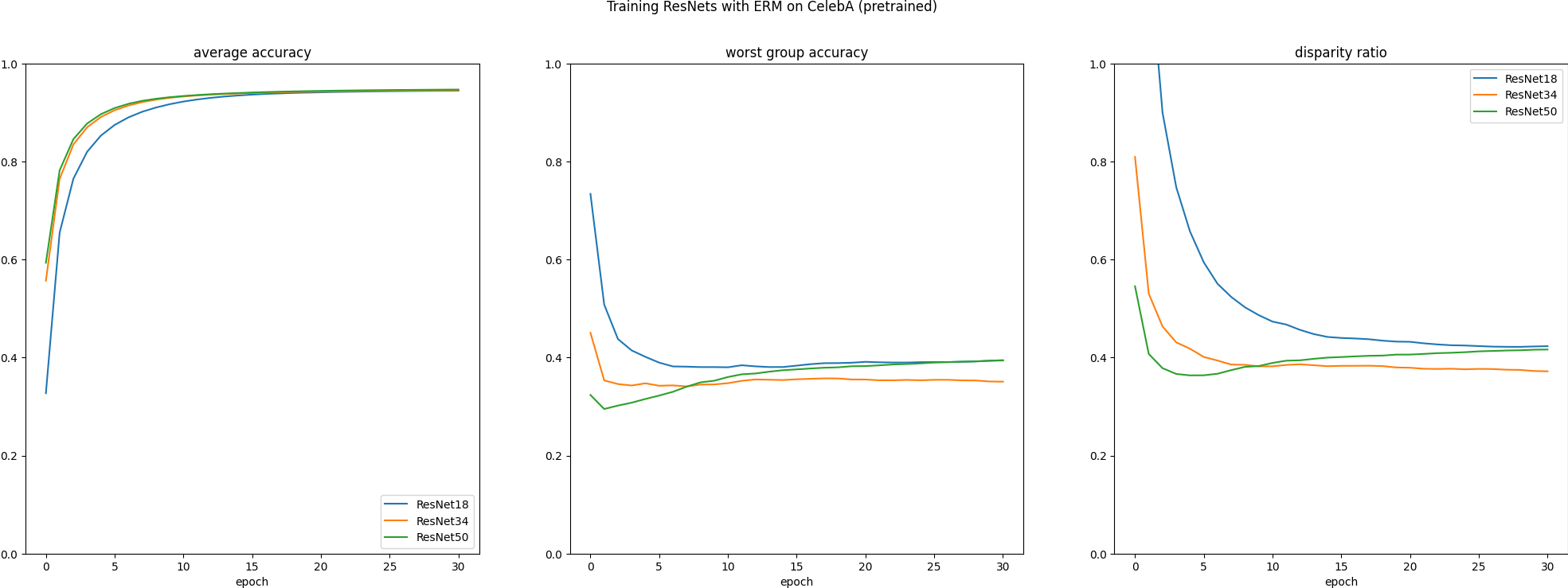
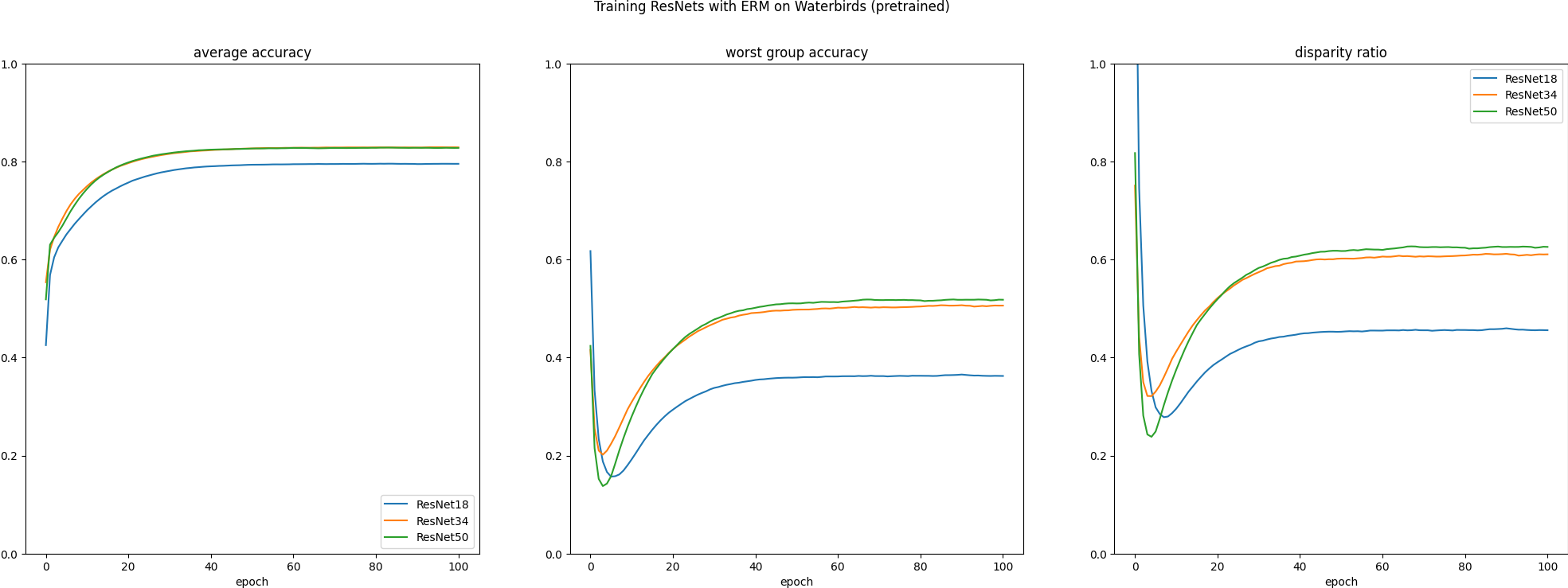
For CelebA, there’s no consistent improvement to the disparity ratio with model scale. For waterbirds, there is a bit of a relationship, and that was true in the limited experiments for the class project as well. This makes me wonder if the hyperparameters are not tuned right for the size of CelebA, which makes me think hyperparameter optimization is going to be valuable in general. I’m working on integrating hyperopt now.